| Yangfan He, Sida Li, Jianhui Wang |
Prompt Learning Based Adaptor for Enhanced Video Editing with Pretrained Text-to-Image Diffusion Models |
| Daiwei Chen, Yi Chen, Aniket Rege, Ramya Korlakai Vinayak |
PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences |
| Brandon Trabucco, Max A Gurinas, Kyle Doherty, Russ Salakhutdinov |
Understanding Visual Concepts Across Models |
| Shanghaoran Quan |
Automatically Generating Custom Context-Driven SFT Data for LLMs with Multi-Granularity |
| Sajad Mousavi, Desik Rengarajan, Ashwin Ramesh Babu, Sahand Ghorbanpour, Vineet Gundecha, Avisek Naug, Soumyendu Sarkar |
Informed Tree of Thought: Cost-efficient Problem Solving with Large Language Models
|
| Gaurav Verma, Rachneet Kaur, Nishan Srishankar, Zhen Zeng, Tucker Balch, Manuela Veloso |
AdaptAgent: Adapting Multimodal Web Agents with Few-Shot Learning from Human Demonstrations
|
| Sazan Mahbub, Caleb Ellington, Sina Alinejad, Kevin Wen, Yingtao Luo, Ben Lengerich, Eric P. Xing |
From One to Zero: RAG-IM Adapts Language Models for Interpretable Zero-Shot Clinical Predictions |
| Yangfan He, Yinghui Xia, Jinfeng Wei, TIANYU SHI, Yang Jingsong |
PM-Jewelry: Personalized Multimodal Adaptation for Virtual Jewelry Try-On with Latent Diffusion
|
| Shuvendu Roy, Ali Etemad |
Leveraging Self Weak-supervision for Improved VLM Performance
|
| Sungmin Cha, Sungjun Cho, Dasol Hwang, Moontae Lee |
Towards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
|
| Yimin Tang, Yurong Xu, Ning Yan, Masood S. Mortazavi |
Enhancing Long Context Performance in LLMs Through Inner Loop Query Mechanism
|
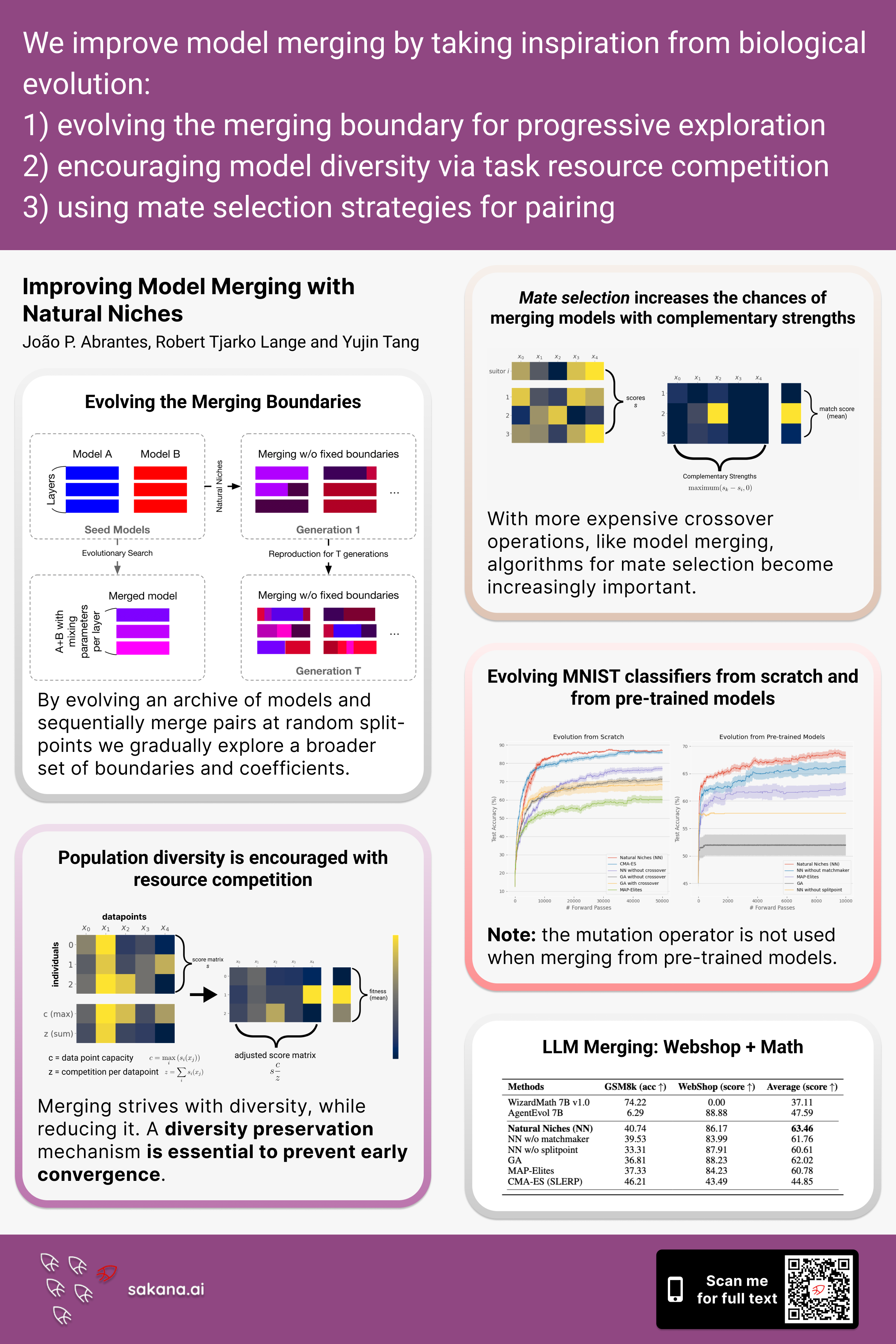
| João Abrantes, Robert Tjarko Lange, Yujin Tang |
Improving Model Merging with Natural Niches
|
| So Kuroki, Taishi Nakamura, Takuya Akiba, Yujin Tang |
Agent Skill Acquisition for LLMs via CycleQD
|
| Asfandyar Azhar, Shaurjya Mandal, Nidhish Shah |
Towards Conversational AI for Spina Bifida Care
|
| Changdae Oh, Yixuan Li, Kyungwoo Song, Sangdoo Yun, Dongyoon Han |
Adapting Foundation Models via Training-free Dynamic Weight Interpolation
|
| Jiajun Chai, Sicheng Li, Yuqian Fu, Dongbin Zhao, Yuanheng Zhu |
Empowering LLM Agents with Zero-Shot Optimal Decision-Making through Q-learning
|
| Hayun Lee, Kiseong Hong, Hwanhee Lee, Sungho Suh, Eunwoo Kim |
Dynamically Managing a Prompt Pool via Self-Enhancement in Continual Learning
|
| Je-Seok Ham, Jia Huang, Peng Jiang, Jinyoung Moon, Yongjin Kwon, Srikanth Saripalli, Changick Kim |
OmniPredict: GPT-4o Enhanced Multi-modal Pedestrian Crossing Intention Prediction |
| Danyang Wang, Lingsong Zhang |
Ensemble-based Offline Reinforcement Learning with Adaptive Behavior Cloning
|
| Bowen Zhao, Leo Parker Dirac, Paulina Varshavskaya |
Can Vision Language Models Learn from Visual Demonstrations of Ambiguous Spatial Reasoning?
|
| Soeun Lee, Si-Woo Kim, Taewhan Kim, Dong-Jin Kim |
IFCap: Image-like Retrieval and Frequency-based Entity Filtering for Zero-shot Captioning |
| Tobias Strangmann, Lennart Purucker, Jörg K.H. Franke, Ivo Rapant, Fabio Ferreira, Frank Hutter |
Transfer Learning for Finetuning Large Language Models |
| Ruoyu Wang, Xiang Li, Tengjiao Sun, Yangfan He, TIANYU SHI, yitingxie |
Uniform Text-Motion Generation and Editing via Diffusion Model
|
| Darian Marlis Rodriguez Vasquez, Afroditi Papadaki |
Generating Diverse Negations from Affirmative Sentences
|
| M. Mehdi Mojarradi, Lingyi Yang, Robert McCraith, Adam Mahdi |
Improving In-Context Learning with Small Language Model Ensembles
|
| Ilya Zisman, Alexander Nikulin, Andrei Polubarov, Lyubaykin Nikita, Vladislav Kurenkov |
N-Gram Induction Heads for In-Context RL: Improving Stability and Reducing Data Needs |
| Alexander Nikulin, Ilya Zisman, Alexey Zemtsov, Vladislav Kurenkov |
XLand-100B: A Large-Scale Multi-Task Dataset for In-Context Reinforcement Learning |
| Zhili Feng, Tanya Marwah, Nicolo Fusi, David Alvarez-Melis, Lester Mackey |
Adapting Language Models via Token Translation
|
| Minju Seo, Jinheon Baek, James Thorne, Sung Ju Hwang |
Retrieval-Augmented Data Augmentation for Low-Resource Domain Tasks |
| Shengran Hu, Cong Lu, Jeff Clune |
Automated Design of Agentic Systems |
| Taewhan Kim, Soeun Lee, Si-Woo Kim, Dong-Jin Kim |
ViPCap: Retrieval Text-based Visual Prompts for Lightweight Image Captioning
|
| Yu Yang, Pan Xu |
Pre-trained Language Models Improve the Few-shot Prompt Ability of Decision Transformer |
| Jonas Hübotter, Sascha Bongni, Ido Hakimi, Andreas Krause |
Efficiently Learning at Test-Time: Active Fine-Tuning of LLMs
|
| Kamalkumar Rathinasamy, Balaji A J, Ankush Kumar, Gagan Gayari, Harshini K, Rajab Ali Mondal, Sreenivasa Raghavan K S, Swayam Singh, Mohammed Rafee Tarafdar |
Narrow Transformer: Mono-lingual Code SLM for Desktop
|
| Qian Yang, Weixiang Yan, Aishwarya Agrawal |
Enhancing Multi-Agent Multi-Modal Collaboration with Fine-Grained Reward Modeling
|
| Gonzalo Martin Garcia, Karim Abou Zeid, Christian Schmidt, Daan de Geus, Alexander Hermans, Bastian Leibe |
Efficient Fine-Tuning of Image-Conditional Diffusion Models for Depth and Surface Normal Estimation |
| Reyhane Askari-Hemmat, Mohammad Pezeshki, Pietro Astolfi, Melissa Hall, Florian Bordes, Jakob Verbeek, Michal Drozdzal, Adriana Romero-Soriano |
Deliberate Practice with Synthetic Data |
| Ognjen Rudovic, Pranay Dighe, Yi Su, Vineet Garg, Sameer Dharur, Xiaochuan Niu, Ahmed Hussen Abdelaziz, Saurabh Adya, Ahmed Tewfik |
Device-Directed Speech Detection for Follow-up Conversations Using Large Language Models |
| Nikolas Gritsch, Qizhen Zhang, Acyr Locatelli, Sara Hooker, Ahmet Üstün |
Nexus: Specialization meets Adaptability for Efficiently Training Mixture of Experts
|
| Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou |
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
|
| Manish Bhattarai, Minh N. Vu, Javier E. Santos, Ismael Boureima, Daniel O'Malley |
Enhancing Cross-Language Code Translation via Task-Specific Embedding Alignment in Retrieval-Augmented Generation |
| Ryan King, Gang Li, Bobak J Mortazavi, Tianbao Yang |
Memory Efficient Continual Learning with CLIP Models |
| Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Linjun Zhang, James Zou, Huaxiu Yao |
MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models |
| Peng Xia, Siwei Han, Shi Qiu, Yiyang Zhou, Zhaoyang Wang, Wenhao Zheng, Zhaorun Chen, Chenhang Cui, Mingyu Ding, Linjie Li, Lijuan Wang, Huaxiu Yao |
MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models |
| Guowei Xu, Mert Yuksekgonul, Carlos Guestrin, James Zou |
metaTextGrad: Learning to learn with language models as optimizers |
| Sahar Rajabi, Sirisha Rambhatla |
Enhancing Fine-Tuning Efficiency of LLMs Through Gradient Subspace Tracking
|
| Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, Robert Tjarko Lange |
Instant Transformer Adaption via HyperLoRA |
| Yi Chen, Muyoung Son, Chuanbo Hua, Joo-Young Kim |
AoP-SAM: Automation of Prompts for Efficient Segmentation
|
| Eric Nuertey Coleman, Luigi Quarantiello, Julio Hurtado, Vincenzo Lomonaco |
Adaptive LoRA Merging for Efficient Domain Incremental Learning
|
| Wenhao Zheng, Yixiao Chen, Weitong Zhang, Souvik Kundu, Yun Li, Zhengzhong Liu, Eric P. Xing, Hongyi Wang, Huaxiu Yao |
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing |
| Vaibhav Singh, Rahaf Aljundi, Eugene Belilovsky |
Controlling Forgetting with Test-Time Data in Continual Learning |
| Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia, Michael Carbin |
Long Context RAG Performance of Large Language Models
|
| Zhenyu Zhu, Yongtao Wu, Quanquan Gu, Volkan Cevher |
Imbalance-Regularized LoRA: A Plug-and-Play Method for Improving Fine-Tuning of Foundation Models |
| Qi Sun, Edoardo Cetin, Yujin Tang |
$\text{Transformer}^2$: Self-adaptive LLMs
|
| Oscar Key, Luka Ribar, Alberto Cattaneo, Luke Hudlass-Galley, Douglas Orr |
Approximate Top-k for Increased Parallelism |
| Ashutosh Ranjan, Vivek Srivastava, Shirish Karande |
Pick Your Influencer: Being Selective is Good for Personalization |
| Daniel Gallo Fernández, Răzvan-Andrei Matișan, Alejandro Monroy Muñoz, Ana Maria Vasilcoiu, Janusz Partyka, Tin Hadži Veljković, Metod Jazbec |
DuoDiff: Accelerating Diffusion Models with a Dual-Backbone Approach
|
| Sam Houliston, Alizée Pace, Alexander Immer, Gunnar Ratsch |
Uncertainty-Penalized Direct Preference Optimization |
| Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, Jianfeng Gao |
SeCom: On Memory Construction and Retrieval for Personalized Conversational Agents
|
| Hyoseo Kim, Dongyoon Han, Junsuk Choe |
NegMerge: Consensual Weight Negation for Strong Machine Unlearning
|
| Zheng Xiong, Siddhant Sharma, Kang Li, Risto Vuorio, Shimon Whiteson |
Efficient Domain Adaptation of Robotic Foundation Models via Hypernetwork-Generated LoRA |
| Felix Stahlberg, Jared Lichtarge, Shankar Kumar |
Dynamic Subset Tuning: Expanding the Operational Range of Parameter-Efficient Training for Large Language Models
|
| Xinyu Yang, Tianqi Chen, Beidi Chen |
APE: Faster and Longer Context-Augmented Generation via Adaptive Parallel Encoding |
| Chanwoo Kim, Jeyoon Yeom, JOOWANG KIM, Suho Kang, Kyungwoo Song |
Efficient Transfer Learning driven by Layer-wise Features Aggregation
|
| Kunal Singh, Mukund Khanna, Pradeep Moturi |
Effective Text-to-Image Alignment with Quality Aware Pair Ranking |
| Mingzhu Shen, Pengtao Chen, Peng Ye, Guoxuan Xia, Tao Chen, Christos-Savvas Bouganis, Yiren Zhao |
MD-DiT: Step-aware Mixture-of-Depths for Efficient Diffusion Transformers
|
| Xiangyu Chen, Ye Wang, Matthew Brand, Pu Perry Wang, Jing Liu, Toshiaki Koike-Akino |
Slaying the HyDRA: Parameter-Efficient Hyper Networks with Low-Displacement Rank Adaptation
|
| Ziheng Cheng, Zhong Li, Jiang Bian |
Data-Efficient Training by Evolved Sampling |
| Quanting Xie, So Yeon Min, Tianyi Zhang, Kedi Xu, Aarav Bajaj, Russ Salakhutdinov, Matthew Johnson-Roberson, Yonatan Bisk |
Embodied-RAG: General Non-parametric Embodied Memory for Retrieval and Generation |
| Zhongmou He, Jing Zhu, Shengyi Qian, Joyce Chai, Danai Koutra |
LinkGPT: Teaching Large Language Models To Predict Missing Links |
| Jianan Zhao, Mikhail Galkin, Hesham Mostafa, Michael M. Bronstein, Zhaocheng Zhu, Jian Tang |
Fully-inductive Node Classification on Arbitrary Graphs
|
| Mudit Verma, Siddhant Bhambri, Subbarao Kambhampati |
Do Think Tags Really Help LLMs Plan? A Critical Evaluation of ReAct-Style Prompting
|
| Ryan Zhang, Herbert Woisetschläger, Shiqiang Wang, Hans Arno Jacobsen |
MESS+: Energy-Optimal Inferencing in Language Model Zoos with Service Level Guarantees
|
| Malyaban Bal, Brian Matejek, Susmit Jha, Adam D. Cobb |
SpikingVTG: Saliency Feedback Gating Enabled Spiking Video Temporal Grounding |
| Gang Li, Wendi Yu, Yao Yao, Wei Tong, Yingbin Liang, Qihang Lin, Tianbao Yang |
Model Developmental Safety: A Safety-Centric Method and Applications in Vision-Language Models |
| So Yeon Min, Xavier Puig, Devendra Singh Chaplot, Tsung-Yen Yang, Akshara Rai, Priyam Parashar, Russ Salakhutdinov, Yonatan Bisk, Roozbeh Mottaghi |
Situated Instruction Following Under Ambiguous Human Intent |
| Yizhu Jiao, Xuchao Zhang, Zhaoyang Wang, Yubo Ma, Zhun Deng, Rujia Wang, Chetan Bansal, Saravan Rajmohan, Jiawei Han, Huaxiu Yao |
Synergistic Weak-Strong Collaboration by Aligning Preferences |
| Xinle Cheng, Zhuoming Chen, Zhihao Jia |
CAT Pruning: Cluster-Aware Token Pruning For Text-to-Image Diffusion Models
|
| Oscar Mañas, Pierluca D'Oro, Koustuv Sinha, Adriana Romero-Soriano, Michal Drozdzal, Aishwarya Agrawal |
Controlling Multimodal LLMs via Reward-guided Decoding
|
| Liangyu Wang, Jie Ren, Hang Xu, Junxiao Wang, David E. Keyes, Di Wang |
ZO-Offloading: Fine-Tuning LLMs with 100 Billion Parameters on a Single GPU
|
| Yuxi Xie, Anirudh Goyal, Xiaobao Wu, Xunjian Yin, Xiao Xu, Min-Yen Kan, Liangming Pan, William Yang Wang |
COrAL: Order-Agnostic Language Modeling for Efficient Iterative Refinement
|
| Wan-Cyuan Fan, Yen-Chun Chen, Mengchen Liu, Lu Yuan, Leonid Sigal |
On Pre-training of Multimodal Language Models Customized for Chart Understanding |
| Steven Kolawole, Keshav Santhanam, Virginia Smith, Pratiksha Thaker |
Extracting Parallelism from Large Language Model Queries
|
| Le Zhang, Qian Yang, Aishwarya Agrawal |
Visual Language Alignment Tuning
|
| Christoph Dann, Yishay Mansour, Teodor Vanislavov Marinov, Mehryar Mohri |
Domain Adaptation for Robust Model Routing |
| Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, Beidi Chen |
MagicPIG: LSH Sampling for Efficient LLM Generation |
| Liangyu Wang, Junxiao Wang, Jie Ren, Zihang Xiang, David E. Keyes, Di Wang |
FlashDP: Memory-Efficient and High-Throughput DP-SGD Training for Large Language Models |
| Xinyu Li, Ruiyang Zhou, Zachary Chase Lipton, Liu Leqi |
Personalized Language Modeling from Personalized Human Feedback |
| Jianan Zhao, Le Zhuo, Yikang Shen, Meng Qu, Kai Liu, Michael M. Bronstein, Zhaocheng Zhu, Jian Tang |
GraphText: Graph Reasoning in Text Space
|
| Dhawal Gupta, Christoph Dann, Alekh Agarwal |
P3O: Pessimistic Preference-based Policy Optimization for Robust Alignment from Preferences |
| Omkar Dige, John Willes, D. B. Emerson |
Evaluating RAG System Performance: The Impact of Knowledge Cut-off and Fine-Tuning |
| Jiafan He, Huizhuo Yuan, Quanquan Gu |
Accelerated Preference Optimization for Large Language Model Alignment
|
| Zhepei Wei, Wei-Lin Chen, Yu Meng |
InstructRAG: Instructing Retrieval Augmented Generation via Self-Synthesized Rationales
|
| Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, Dong Yu |
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory |
| Neeratyoy Mallik, Maciej Janowski, Johannes Hog, Herilalaina Rakotoarison, Aaron Klein, Josif Grabocka, Frank Hutter |
Warmstarting for Scaling Language Models
|
| Xiujun Li, Yujie Lu, William Yang Wang, Yejin Choi |
Text as Images: Can Multimodal Large Language Models Follow Printed Instructions in Pixels? |
| Aniket Rajiv Didolkar, Andrii Zadaianchuk, Rabiul Awal, Maximilian Seitzer, Efstratios Gavves, Aishwarya Agrawal |
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning |
| Artur Parkhimchyk, Amirreza Naziri, Laleh Seyyed-Kalantari |
Exploring Visual Prompt Tuning for Demographic Adaptation in Foundation Models for Medical Imaging |
| Yuji Byun, Jaeho Lee |
Towards Federated Low-Rank Adaptation with Rank Heterogeneity |
| Edouardo Honig, Andrew Lizarraga, Zijun Frank Zhang, Ying Nian Wu |
Better Prompt Compression Without Multi-Layer Perceptrons |
| Zahra Rahimi Afzal, Tara Esmaeilbeig, Mojtaba Soltanalian, Mesrob I Ohannessian |
Can the Spectrum of the Neural Tangent Kernel Anticipate Fine-Tuning Performance?
|
| Hui Yuan, Yifan Zeng, Yue Wu, Huazheng Wang, Mengdi Wang, Liu Leqi |
A Common Pitfall of Margin-based Language Model Alignment: Gradient Entanglement
|
| Song Jiang, Da JU, Andrew Cohen, Sasha Mitts, Aaron Foss, Justine T Kao, Xian Li, Yuandong Tian |
Towards Full Delegation: Designing Ideal Agentic Behaviors for Travel Planning
|
| Bo Wen, Xin Zhang |
Enhancing Reasoning to Adapt Large Language Models for Domain-Specific Applications
|
| Megh Thakkar, Yash More, Quentin Fournier, Matthew Riemer, Pin-Yu Chen, Amal Zouaq, Payel Das, Sarath Chandar |
Combining Domain and Alignment Vectors to Achieve Better Knowledge-Safety Trade-offs in LLMs |
| Allison Lau, Younwoo Choi, Vahid Balazadeh, Keertana Chidambaram, Vasilis Syrgkanis, Rahul Krishnan |
Personalized Adaptation via In-Context Preference Learning
|
| Muhammad Arbab Arshad, Talukder Zaki Jubery, Asheesh K Singh, ARTI SINGH, Chinmay Hegde, Baskar Ganapathysubramanian, Aditya Balu, Adarsh Krishnamurthy, Soumik Sarkar |
Assisted Few-Shot Learning for Vision-Language Models in Agricultural Stress Phenotype Identification
|
| Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee |
REGENT: A Retrieval-Augmented Generalist Agent That Can Act in-Context In New Environments
|
| Hao Zhao, Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion |
Is In-Context Learning Sufficient for Instruction Following in LLMs?
|
| Huisheng Wang, Zhuoshi Pan, Hangjing Zhang, Mingxiao Liu, Yiqing Lin, H. Vicky Zhao |
InvestAlign: Align LLMs with Investor Decision-Making under Herd Behavior
|
| Tianyun Yang, Ziniu Li, Juan Cao, Chang Xu |
Mitigating Hallucination in Large Vision-Language Models via Modular Attribution and Intervention |
| Megh Thakkar, Léo Boisvert, Thibault Le Sellier de Chezelles, Alexandre Piché, Maxime Gasse, Alexandre Lacoste, Massimo Caccia |
AgentMerge: Enhancing Generalization in Fine-Tuned LLM Agents
|
| Sara Kangaslahti, David Alvarez-Melis |
Continuous Language Model Interpolation for Dynamic and Controllable Text Generation |
| Himanshu Thakur, Eshani Agrawal, Smruthi Mukund |
Personas within Parameters: Fine-Tuning Small Language Models with Low-Rank Adapters to Mimic User Behaviors
|
| Nikki Lijing Kuang, Wei Sun, Scott McFaddin, Yian Ma, Markus Ettl |
Towards Personalized Language Models via Inference-time Human Preference Optimization |
| Chang Liu, Saad Hossain, C Thomas, Kwei-Herng Lai, Raviteja Vemulapalli, Sirisha Rambhatla, Alexander Wong |
LangDA: Language-guided Domain Adaptive Semantic Segmentation
|
| Yang Zhou, Zhuoming Chen, Zhaozhuo Xu, Xi Victoria Lin, Beidi Chen |
Sirius: Contextual Sparsity with Correction for Efficient LLM
|
| Emiliyan Gospodinov, Vaisakh Shaj, Philipp Becker, Stefan Geyer, Gerhard Neumann |
Adaptive World Models: Learning Behaviors by Latent Imagination Under Non-Stationarity
|
| Brian K Chen, Tianyang Hu, Hui Jin, Hwee Kuan Lee, Kenji Kawaguchi |
In-Context Learning behaves as a greedy layer-wise gradient descent algorithm
|
| Hari Chandana Kuchibhotla, Abbavaram Gowtham Reddy, Sai Srinivas Kancheti, Vineeth N. Balasubramanian |
Fine-Grained Visual Recognition in the Age of Multimodal LLMs |
{kind=link}